
Light RAT-SQL: A RAT-SQL with More Abstraction and Less Embedding of Pre-existing Relations
Abstract:
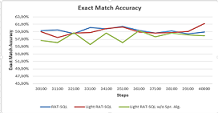
RAT-SQL is among
the popular framework used in the Text-To-SQL challenges for jointly encoding the
database relations and questions in a way to improve the semantic parser. In this
work, we propose a light version of the RAT-SQL where we dramatically reduced the
number of the preexisting relations from 55 to 7 (Light RAT-SQL-7) while preserving
the same parsing accuracy. To ensure the effectiveness of our approach, we trained
a Light RAT-SQL-2, (with 2 embeddings) to show that there is a statistically significant
difference between RAT-SQL and Light RAT-SQL-2 while Light RAT-SQL-7 can compete
with RAT-SQL.
References:
[1] B. Wang, R.
Shin, X. Liu, O. Polozov, and M. Richardson (2020): “RAT-SQL: Relation-Aware
Schema Encoding and Linking for Text-to-SQL Parsers, . [Online]. Available: https://github.com/Microsoft/rat-sql.
[2] B. Hui et al
(Mar. 2022): “S$^2$SQL: Injecting Syntax to Question-Schema Interaction Graph
Encoder for Text-to-SQL Parsers, [Online]. Available: http://arxiv.org/abs/2203.06958.
[3] T. Scholak,
R. Li, D. Bahdanau, H. de Vries, and C. Pal (Oct. 2020): “DuoRAT: Towards
Simpler Text-to-SQL Models, doi: 10.18653/v1/2021.naacl-main.103.
[4] T. Yu et al
(Sep. 2020), “GraPPa: Grammar-Augmented Pre-Training for Table Semantic
Parsing, [Online]. Available: http://arxiv.org/abs/2009.13845.
[5] Z. Lan et al
(2020): “Albert: A Lite Bert For Self-Supervised Learning Of Language
Representations. [Online]. Available: https://github.com/google-research/ALBERT.
[6] J. Devlin,
Ming-Wei Chang, Kenton Lee, and Kristina Toutanova Bert-Ppt (2018): “BERT:
Pre-training of Deep Bidirectional Transformers for Language Understanding
(Bidirectional Encoder Representations from Transformers).
[7] E. Voita, D.
Talbot, F. Moiseev, R. Sennrich, and I. Titov (2019), “Analyzing Multi-Head
Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be
Pruned,” [Online]. Available: https://github.com/.
[8] E. F. Codd (1974),
“Recent Investigations in Relational Data Base Systems,” in IFIP Congress.
[9] A. Suhr, S.
Iyer, Y. Artzi, and P. G. Allen (2018), “Learning to Map Context-Dependent
Sentences to Executable Formal Queries. [Online]. Available: https://github.com/clic-lab/atis.
[10] S. Iyer, I.
Konstas, A. Cheung, J. Krishnamurthy, and L. Zettlemoyer (Apr. 2017): “Learning
a Neural Semantic Parser from User Feedback, [Online]. Available: http://arxiv.org/abs/1704.08760.
[11] J. Herzig
and J. Berant (Apr. 2018): “Decoupling Structure and Lexicon for Zero-Shot
Semantic Parsing, [Online]. Available: http://arxiv.org/abs/1804.07918.
[12] A. Kamath
and R. Das (Dec. 2018), “A Survey on Semantic Parsing”, [Online]. Available: http://arxiv.org/abs/1812.00978.
[13] L. Dong and
M. Lapata (May 2018): “Coarse-to-Fine Decoding for Neural Semantic Parsing”,
[Online]. Available: http://arxiv.org/abs/1805.04793.
[14] L. Dong and
M. Lapata (Jan. 2016): “Language to Logical Form with Neural Attention”,
[Online]. Available: http://arxiv.org/abs/1601.01280.
[15] O. Goldman,
V. Latcinnik, U. Naveh, A. Globerson, and J. Berant (Nov. 2017):
“Weakly-supervised Semantic Parsing with Abstract Examples,”, [Online].
Available: http://arxiv.org/abs/1711.05240.
[16] P. Yin and
G. Neubig (Oct. 2018): “TRANX: A Transition-based Neural Abstract Syntax Parser
for Semantic Parsing and Code Generation”, [Online]. Available: http://arxiv.org/abs/1810.02720.
[17] P. Yin and
G. Neubig (Apr. 2017), “A Syntactic Neural Model for General-Purpose Code
Generation”, [Online]. Available: http://arxiv.org/abs/1704.01696.
[18] C. Xiao, M.
Dymetman, and C. Gardent (2016): “Sequence-based Structured Prediction for
Semantic Parsing,” [Online]. Available: https://github.com/percyliang/sempre.
[19] J.
Krishnamurthy, P. Dasigi, and M. Gardner (2017): “Neural Semantic Parsing with
Type Constraints for Semi-Structured Tables.
[20] V. L. Shiv
and C. Quirk (2019): “Novel positional encodings to enable tree-based
transformers,” in Advances in Neural Information Processing Systems, vol. 32.
[21] Q. He, J.
Sedoc, and J. Rodu (Dec. 2021): “Trees in transformers: a theoretical analysis
of the Transformer’s ability to represent trees, [Online]. Available: http://arxiv.org/abs/2112.11913.
[22] N. Kitaev,
Ł. Kaiser, and A. Levskaya (Jan. 2020): “Reformer: The Efficient Transformer”,
[Online]. Available: http://arxiv.org/abs/2001.04451.
[23] A. Vaswani
et al (Jun. 2017): “Attention Is All You Need”, [Online]. Available: http://arxiv.org/abs/1706.03762.
[24] J. Guo et al
(2019): “Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate
Representation.
[25] R. Cao, L.
Chen, Z. Chen, Y. Zhao, S. Zhu, and K. Yu (Jun. 2021): “LGESQL: Line Graph
Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations, [Online].
Available: http://arxiv.org/abs/2106.01093.
[26] X. V. Lin,
R. Socher, and C. Xiong (Dec. 2020): “Bridging Textual and Tabular Data for
Cross-Domain Text-to-SQL Semantic Parsing”, [Online]. Available: http://arxiv.org/abs/2012.12627.
[27] A. Gur, S.
Yavuz, Y. Su, and X. Yan, “DialSQL: Dialogue Based Structured Query Generation.
[28] B. Bogin, M.
Gardner, and J. Berant (2019): “Global Reasoning over Database Structures for
Text-to-SQL Parsing.
[29] B. Bogin, M.
Gardner, and J. Berant (Apr. 08, 2022): “Representing Schema Structure with
Graph Neural Networks for Text-to-SQL Parsing,” pp. 4560–4565, 2019, Accessed
[Online]. Available: https://github.com/benbogin/.
[30] C. Xu, W. Zhou,
T. Ge, F. Wei, and M. Zhou (2020), “BERT-of-Theseus: Compressing BERT by
Progressive Module Replacing . [Online]. Available: https://en.wikipedia.org/wiki/Ship_.
[31] M. Shoeybi,
M. Patwary, R. Puri, P. Legresley, J. Casper, and B. Catanzaro, “Megatron-LM (2020):
Training Multi-Billion Parameter Language Models Using Model Parallelism,”
[Online]. Available: https://github.com/.
[32] V. Sanh, L.
Debut, J. Chaumond, and T. Wolf (Oct. 2019): “Distilbert, a distilled version
of BERT: smaller, faster, cheaper and lighter, [Online]. Available: http://arxiv.org/abs/1910.01108.
[33] M. Lewis et
al (Oct. 2019): “BART: Denoising Sequence-to-Sequence Pre-training for Natural
Language Generation, Translation, and Comprehension, [Online]. Available: http://arxiv.org/abs/1910.13461.
[34] Alec
Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever (2018):
“Improving Language Understanding by Generative Pre-Training, [Online].
Available: https://gluebenchmark.com/leaderboard.
[35] A. Radford,
J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever (2019): “Language Models
are Unsupervised Multitask Learners, [Online]. Available: https://github.com/codelucas/newspaper.
[36] Y. Liu et al
(Jul. 2019): “RoBERTa: A Robustly Optimized BERT Pretraining Approach,”
[Online]. Available: http://arxiv.org/abs/1907.11692.
[37] T. Wolf et
al (Oct. 2019): “HuggingFace’s Transformers: State-of-the-art Natural Language
Processing” [Online]. Available: http://arxiv.org/abs/1910.03771.
[38] T. B. Brown
et al (2020): “Language Models are Few-Shot Learners. [Online]. Available: https://commoncrawl.org/the-data/.
[39] W. Fedus, B.
Zoph, and N. Shazeer (2022): “Switch Transformers: Scaling to Trillion
Parameter Models with Simple and Efficient Sparsity.
[40] K. Clark,
M.-T. Luong, Q. v. Le, and C. D. Manning (Mar. 2020): “Electra: Pre-training
Text Encoders as Discriminators Rather Than Generators, [Online]. Available: http://arxiv.org/abs/2003.10555.
[41] T. Scholak,
N. Schucher, and D. Bahdanau (Sep. 2021): “PICARD: Parsing Incrementally for
Constrained Auto-Regressive Decoding from Language Models [Online]. Available: http://arxiv.org/abs/2109.05093.
[42] C. Raffel et
al (Oct. 2019): “Exploring the Limits of Transfer Learning with a Unified
Text-to-Text Transformer, [Online]. Available: http://arxiv.org/abs/1910.10683.
[43] J. Herzig,
P. K. Nowak, T. Müller, F. Piccinno, and J. Eisenschlos (2020): “TaPas: Weakly
Supervised Table Parsing via Pre-training, . doi: 10.18653/v1/2020.acl-main.398.
[44] L. Zhao, H.
Cao, and Y. Zhao (Jan. 2021) “GP: Context-free Grammar Pre-training for
Text-to-SQL Parsers,” [Online]. Available: http://arxiv.org/abs/2101.09901.
[45] X. Deng, A.
H. Awadallah, C. Meek, O. Polozov, H. Sun, and M. Richardson (Oct. 2020),
“Structure-Grounded Pretraining for Text-to-SQL,” doi:
10.18653/v1/2021.naacl-main.105.
[46] P. Yin, G.
Neubig, W. Yih, and S. Riedel (May 2020): “TaBERT: Pretraining for Joint
Understanding of Textual and Tabular Data,” pp. 8413–8426, doi:
10.48550/arxiv.2005.08314.
[47] P. Shaw, J.
Uszkoreit, G. Brain, and A. Vaswani (2018): “Self-Attention with Relative
Position Representations.
[48] O. Vinyals,
M. Fortunato, and N. Jaitly (Jun. 2015): “Pointer Networks,” [Online].
Available: http://arxiv.org/abs/1506.03134.
[49] M. Schuster
and K. K. Paliwal (1997): “Bidirectional recurrent neural networks,” IEEE
Transactions on Signal Processing, vol. 45, no. 11, doi: 10.1109/78.650093.
[50] K. Cho, B.
van Merriënboer, D. Bahdanau, and Y. Bengio (2014): “On the properties of
neural machine translation: Encoder–decoder approaches,” in Proceedings of SSST
2014 - 8th Workshop on Syntax, Semantics and Structure in Statistical
Translation. doi: 10.3115/v1/w14-4012.
[51] S.
Hochreiter and J. Schmidhuber (1997): “Long Short-Term Memory,” Neural Comput,
vol. 9, no. 8, doi: 10.1162/neco.1997.9.8.1735.
[52] T. Yu et al
(Sep. 2018): “Spider: A Large-Scale Human-Labeled Dataset for Complex and
Cross-Domain Semantic Parsing and Text-to-SQL Task,” [Online]. Available: http://arxiv.org/abs/1809.08887.
[53] C. D.
Manning, M. Surdeanu, J. Bauer, J. Finkel, S. J. Bethard, and D. Mcclosky (2014),
“The Stanford CoreNLP Natural Language Processing Toolkit.
[54] J.
Pennington, R. Socher, and C. D. Manning (2014): “GloVe: Global Vectors for
Word Representation, [Online]. Available: http://nlp.
[55] Y. Gal and
Z. Ghahramani (2016): “A Theoretically Grounded Application of Dropout in
Recurrent Neural Networks.
[56] A. Paszke et
al (2019): “PyTorch: An Imperative Style, High-Performance Deep Learning
Library.
[57] D. P. Kingma
and J. Ba (Dec. 2014): “Adam: A
Method for Stochastic Optimization, [Online]. Available: http://arxiv.org/abs/1412.6980.
